Unlocking Structured Data Extraction from Images
Discover how DialectAI provides secure, on-premise data extraction and OCR solutions for image documents that ensure data security and offer cost-effective processing for sensitive or high-volume datasets, eliminating the need for complex manual data cleaning.


In today’s competitive business landscape, the ability to convert vast amounts of unstructured data in images into structured, actionable insights is paramount. Companies increasingly rely on optical character recognition (OCR) and advanced artificial intelligence (AI) models to automate document processing, reduce manual entry, and integrate critical information directly into their business systems. At DialectAI, we specialize in delivering custom AI & OCR services tailored to the unique needs of modern enterprises. In this article, we’ll explore the various approaches to structured data extraction from images, compare the underlying model technologies.
The Challenge of Data Extraction from Diverse Image Inputs
Organizations today work with a wide variety of image inputs, for example printed documents, scanned forms, skewed camera images, handwritten notes, and mixed-format documents such as invoices or questionnaires with multiple choice elements. Each input type poses unique challenges:
- Printed and Scanned Documents: These are generally the easiest to process, though issues such as skew or low image quality can affect OCR accuracy.
- Handwritten Text and Forms: Extracting handwritten data requires advanced recognition capabilities. Handwritten forms add further complexity due to the variability in handwriting styles.
- Multi-Choice Elements: Checkboxes, radio buttons, and other selection marks often present additional hurdles. Standard OCR models may simply extract these elements as graphic marks or ignore them altogether, missing critical information used in surveys or registration forms (for example, identifying a gender choice).
The need to accommodate such diversity necessitates the use of versatile and robust OCR solutions in which AI and machine learning play a vital role.
Approaches to Structured Data Extraction
Businesses can choose from several technical pathways to implement OCR systems for structured data extraction. Let’s consider three primary approaches:
1. Traditional OCR Models with CPU Processing
Traditional OCR systems such as Tesseract are well known and widely deployed. These models primarily run on CPU-based systems. The workflow typically follows these steps:
- Text Detection: Text detection engine identifies regions of interest and extracts the bounding box coordinates
- Text Extraction: The OCR engine helps convert these detected text-boxes into plain text.
- Post-Processing with LLMs: Once the text is extracted, a large language model (LLM) can parse, reason, clean and structure the text into relevant JSON fields.
This approach leverages the strengths various traditional OCR engines for text extraction and LLMs for organizing data.
This method is cost effective, operates on CPU hardware and integrates well with LLM APIs provisioned on any cloud, but has limitations in terms of precision, especially with complex layouts or selection marks.




Traditional OCR involves text detection, cropping the bounding boxes and text recognition. We see the original image, the corresponding segmentation map, output from the text detection model and extracted text reconstituted as per the original bounding box coordinates.
2. GPU-Accelerated OCR Models
Advanced OCR models running on GPUs utilize state-of-the-art deep learning algorithms. In these systems:
- Classification & Layouts: Performs layout analysis, bounding box classification (for example title, FigureCaption, Table, Text, ListItem, etc.,) and reading order detection
- Enhanced Extraction Capabilities: GPU models handle larger volumes of data and work faster
- LLM Integration for JSON Structuring: Similar to traditional methods, an LLM is called to convert the OCR output into a structured format.
These models are ideally suited for enterprises that process thousands of documents daily, balancing both speed and precision for complex image inputs.


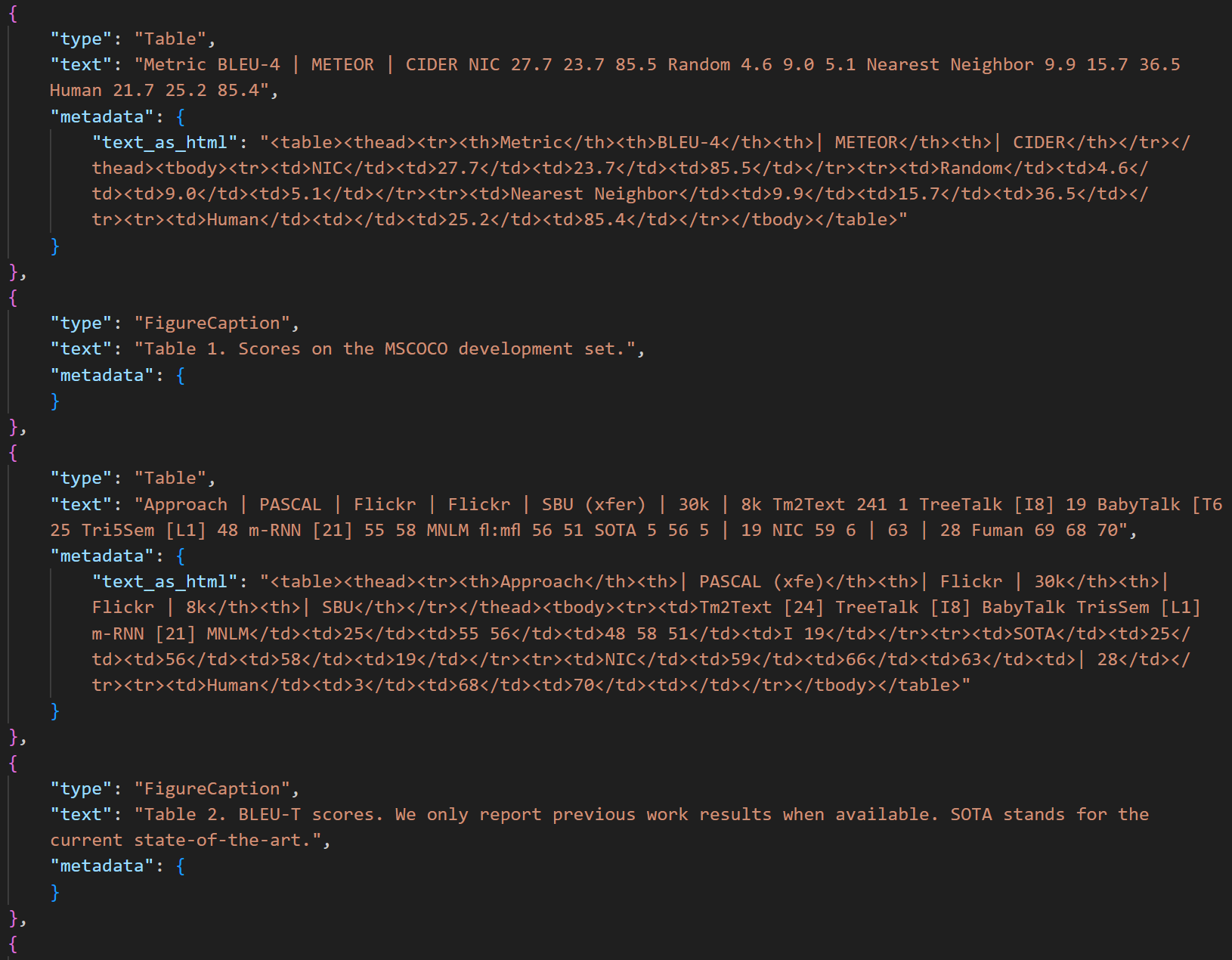
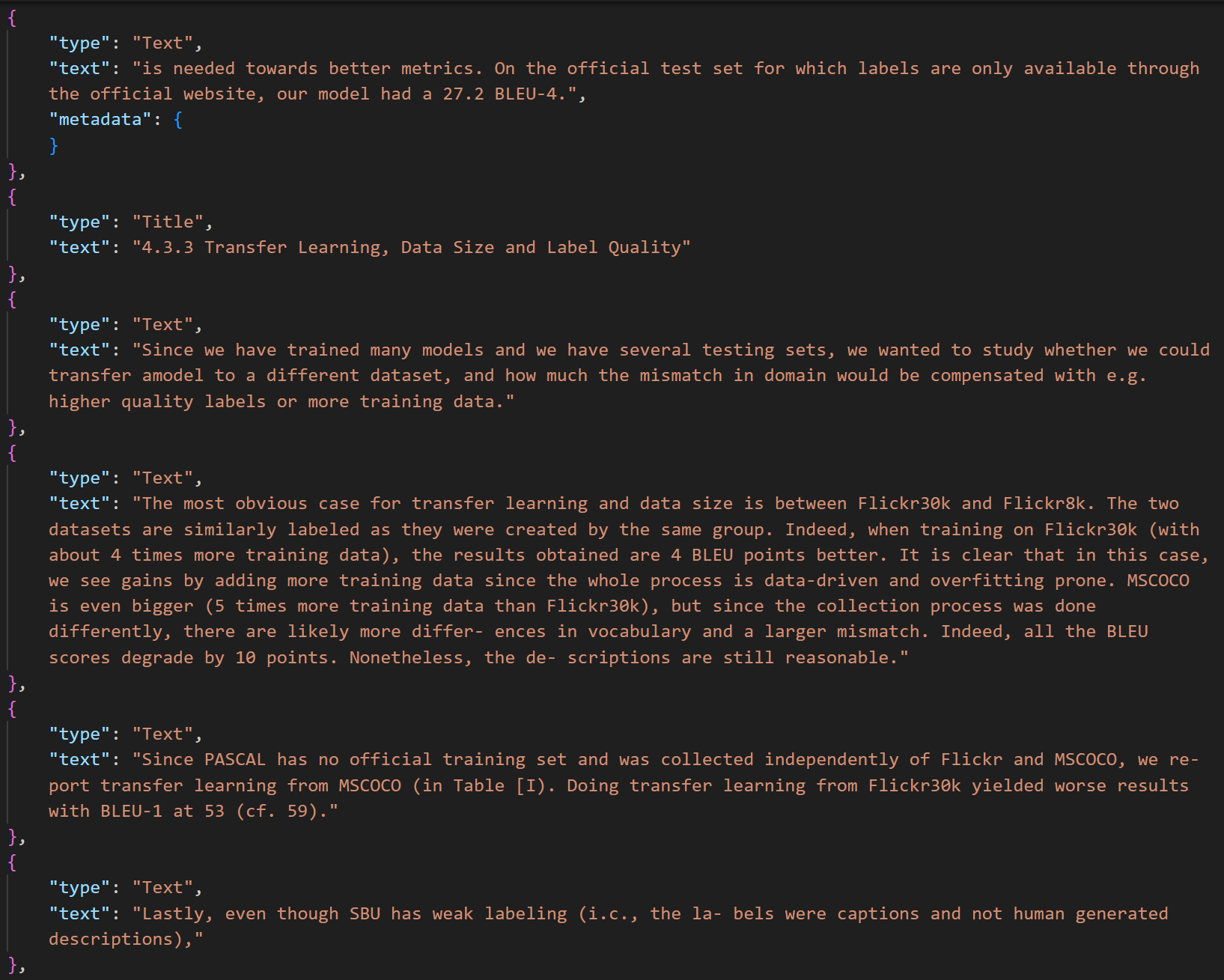
Current generation of OCR capabilities include layout analysis, bounding box classification (table, text, title, captions for tables and figures), reading order detection, handwriting recognition, curved text extraction and table's layout, text and html extraction in an easy to automate JSON format.
3. Multimodal LLM Models
The latest frontier in document extraction comes from multimodal LLMs. These models combine text and image understanding in a single framework:
- Simultaneous Image and Text Processing: Multimodal models take both the image and the extracted text to yield a richer, more context-aware understanding of the document.
- Advanced Deciphering of Selection Marks: They are particularly adept at handling checkboxes, radio buttons, and other intricate-ambiguous elements that standard OCR often misses.
- Robust Data Structuring: By integrating visual cues directly into the model’s inference process, these models can more accurately delineate the spatial and contextual relationships between text blocks, selections, and form elements.
For businesses that require high levels of precision in multi-format documents or need to extract non-standard elements, the multimodal approach offers significant advantages over standalone text-based OCR.


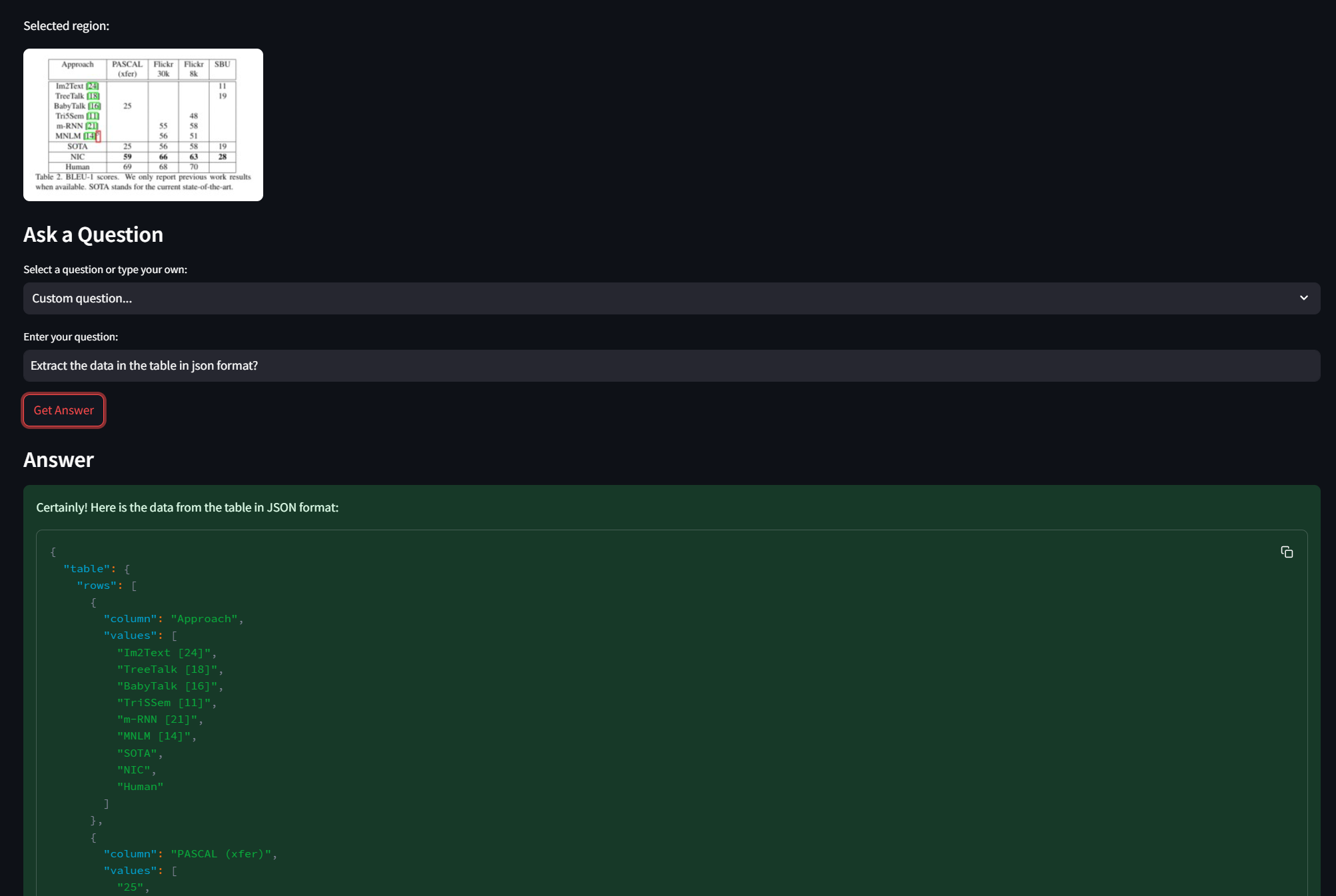
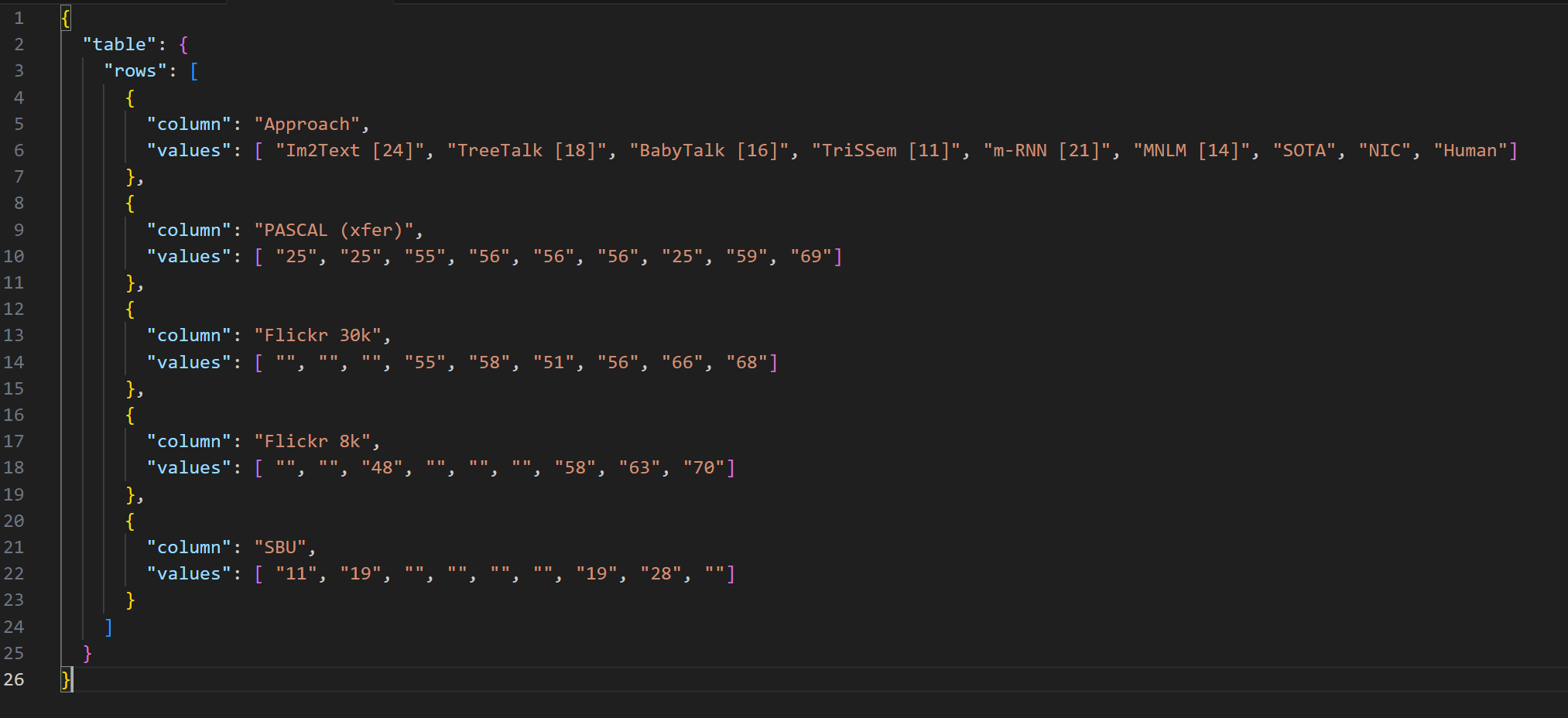
Secure, Self-Hosted Workflows for Critical and High-Volume Datasets
When your business handles mission-critical, proprietary data that cannot leave your digital perimeter, self-hosting your document extraction workflows is essential. This not only ensures that sensitive data stays secure but also offers significant cost benefits, especially for processing high-volume datasets. Below is a streamlined overview of the key challenges and the advantages of advanced extraction methods, along with a look at how DialectAI can help.
Challenges with Traditional OCR Approaches
- Jumbled Data Output:
- OCR output often mirrors the original image layout.
- Extracted text remains unstructured, making it difficult to use directly.
- Manual Data Cleanup:
- Reliance on regex and manual text-cleaning is error-prone.
- Maintaining custom cleaning routines for varied document formats is cumbersome.
Advantages of LLM-Based and Multimodal Extraction
- Intelligent Data Restructuring:
- Uses LLMs or multimodal LLMs to intelligently reformat extracted data.
- Automatically converts unstructured text into structured, database-ready formats.
- Enhanced Accuracy & Integration:
- Understands context, relationships, and spatial cues within the document.
- Eliminates the hassle of managing manual regex/text cleaning.
- Structured output streamlines integration with downstream analytics and databases.
Enterprise OCR Options
When clients opt for custom data extraction, the typical use case involves specifying exactly which fields need to be extracted from a collection of images. This structured information is then pushed into a database for further processing, analytics, or integration into enterprise workflows.
Here’s a snapshot of common pricing structures from various providers:
- Azure Document Intelligence:
- Custom Extraction: Approximately $30–$50 per 1,000 pages in a pay-as-you-go model. For high-volume usage, commitment tiers may offer additional discounts.
- Read calls, hosting, and additional services may incur extra fees based on usage and throughput.
- Google Cloud Document AI:
- Custom Extractor pricing is often around $30 per 1,000 pages, plus potential charges for deploying a processing endpoint. Google’s model frequently requires planning for both extraction costs and any additional hosting fees.
- Amazon Textract:
- Basic OCR and form data extraction can start from as little as $1.50 per 1,000 pages, though additional advanced features such as custom queries may be billed at higher rates (for example, $15 per 1,000 pages).
- The pricing model emphasizes a pay-for-what-you-use approach, ideal for scalable workloads.
Enterprise Solutions from DialectAI
DialectAI specializes in economically hosting and managing advanced OCR pipelines, either on-premises or across multi-cloud environments.
Our solutions provide:
- Data Control: Keeps all sensitive information within your infrastructure.
- Cost Efficiency: Significantly lower pricing compared to cloud providers.
- Seamless Integration: Custom pipelines that directly feed structured, actionable data into your enterprise databases and systems.
| Model Type | Custom Extraction Cost |
|---|---|
| CPU-Based Models | INR 0.1 (or $0.0012) per image |
| Multimodal GPU Models | INR 0.2 (or $0.0024) per image |
Accurate & Automated Image Extraction
Structured data extraction from images is rapidly becoming a cornerstone of digital transformation across industries. By leveraging cutting-edge OCR models (from traditional CPU-based engines to GPU-accelerated and even multimodal LLMs) businesses are better positioned to automate image processing, reduce manual input, and integrate key data seamlessly into their operations.
We understand that no single approach fits all scenarios. That’s why we offer custom AI & OCR services that tailor the solution to your specific needs:
- cost-effective,
- CPU-based system for high-volume text extraction,
- a GPU-accelerated model for rapid processing of complex documents,
- or a multimodal LLM that can accurately decipher intricate elements such as checkboxes and radio buttons
Our in-depth knowledge of flexible deployment options and cloud pricing models ensures that you achieve both high accuracy and cost efficiency for your unique business requirements.
With DialectAI as your trusted partner, you can efficiently transform your document processing into a secure, scalable, and economically competitive backbone for your enterprise workflows.
Ready to unlock the power of your documents? Contact DialectAI today for a free demo and discover how our custom AI & OCR solutions can transform your business processes from manual, error-prone tasks to streamlined, automated workflows.
Feel free to share this article with your colleagues or reach out in the comments below if you have any questions or want to explore specific OCR solutions tailored for your enterprise.